Incident: Service disruption 2023-04-06 22:54 - 2023-04-07 08:22
Outage fediverse.foundation services 2023-04-06 - postmortem
Summary
| Type |
Incident |
| Summary |
Unplanned automatic update of the metallb OKD loadbalancer components |
| Impact |
Full outage of all services on OKD cluster |
| Duration | 9:28h |
| Status |
Resolved |
| Reporter(s) |
@damadmai, @paula |
| Responder(s) |
@b2c, @fossie |
| Internal reference |
/boards/team/kxr1rdhhqtb47muhr3kucn5mxe/bnqecfsesxi8x3pkdm6ahbqf1gy/v48sbw7m8hfn95y9u78fezy3s6o/c5ciqgju3ajnu7q74n3qrnf9dih |
| Service graphs |
|
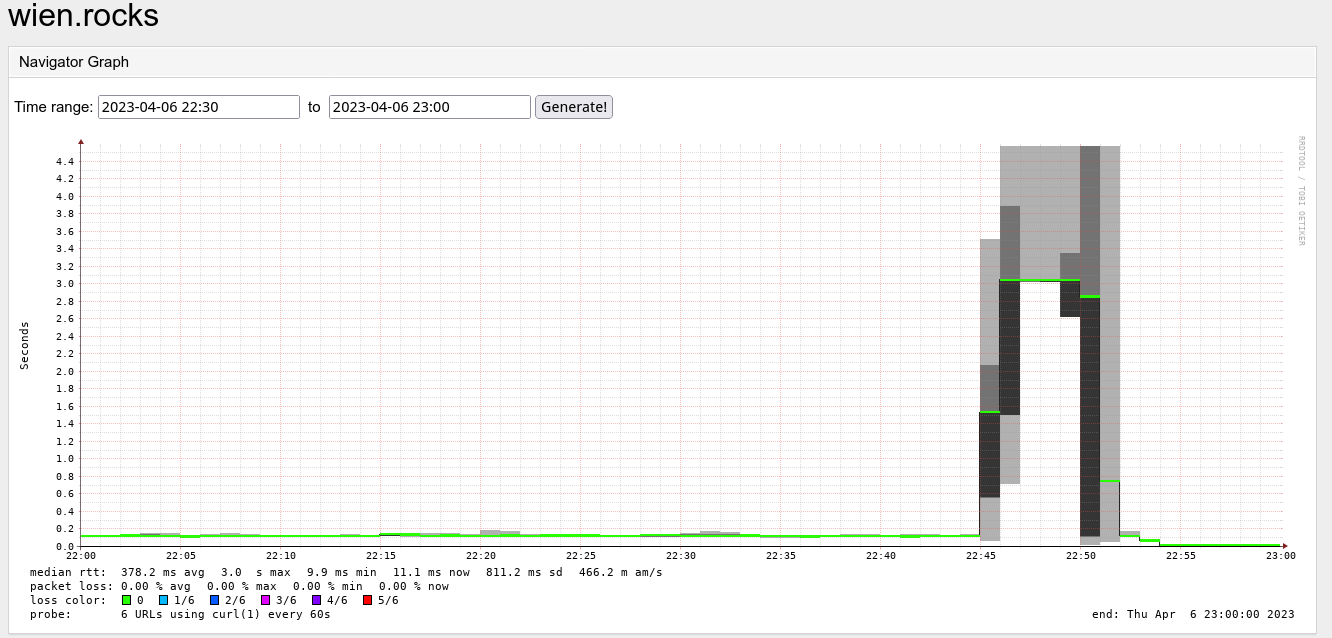
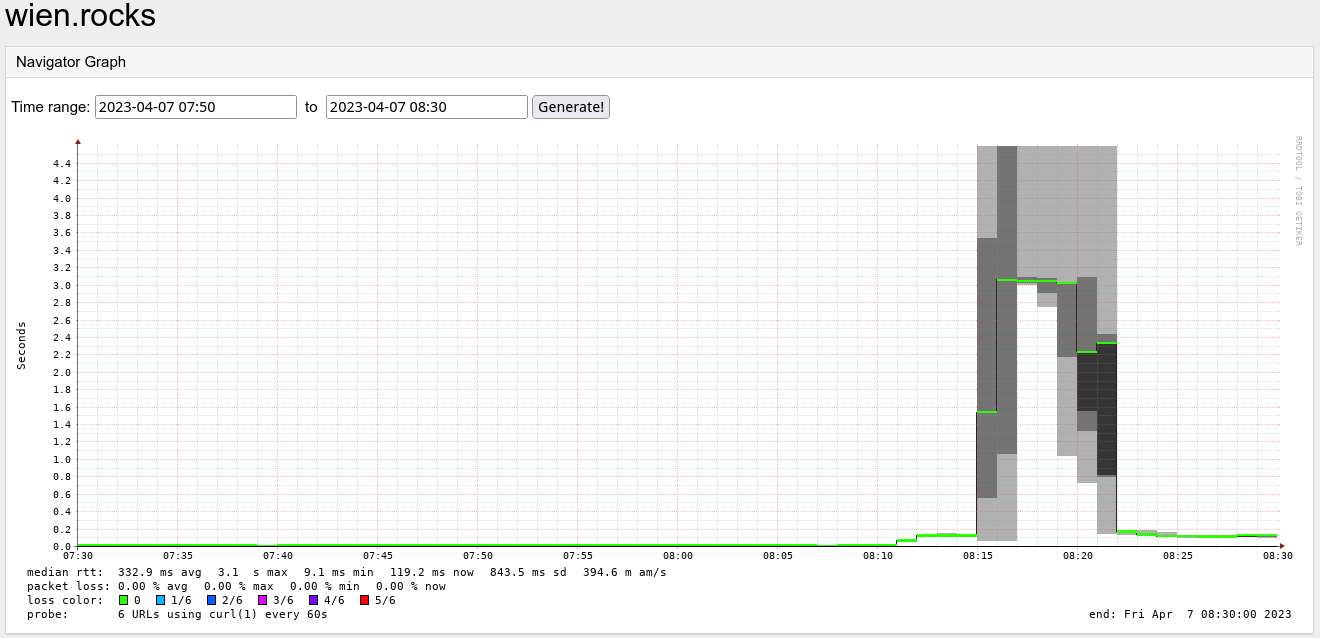
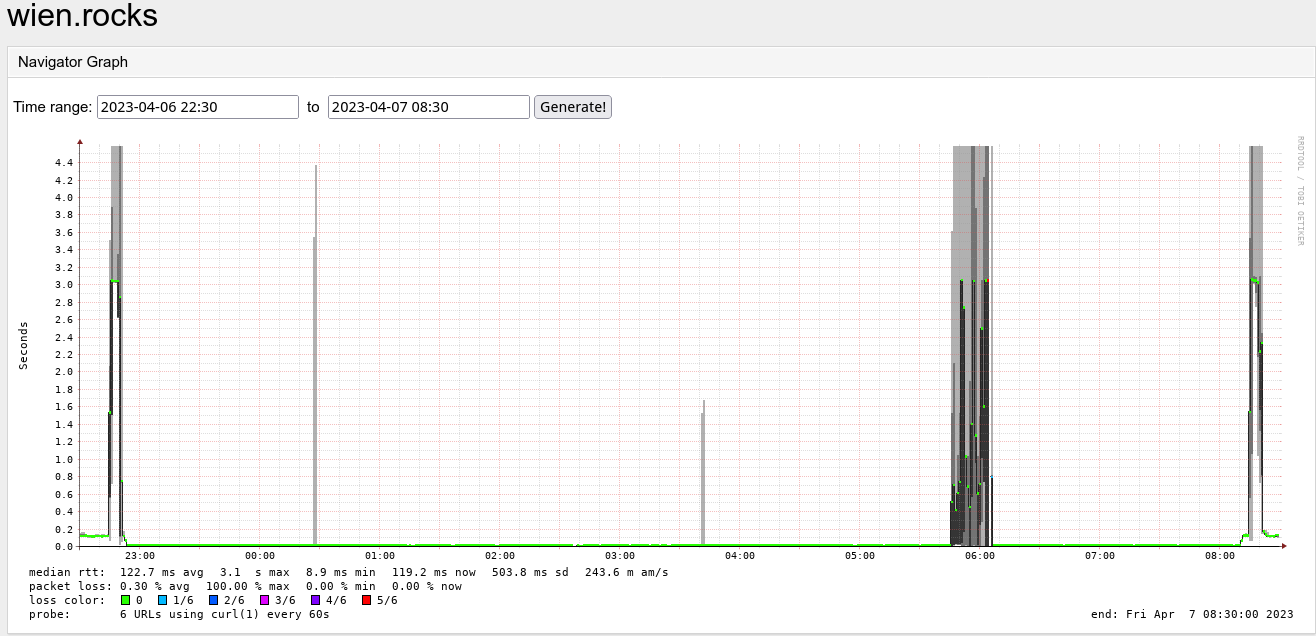
Symptoms
All services hosted on OKD unreachable from the internet although containers and middle/backend services up and running. Applications expose "connection reset" behaviour although public VIP reachable. Ingress container up, but shows no incoming connections. Hardware network components functional, routing working as expected.
These symptoms point to a failure of an OKD infrastructure component.
Investigation
Further investigation of the OKD loadbalancer component metallb shows multiple restarts of containers:
NAME READY STATUS RESTARTS AGE
controller-65698489c4-8kk49 1/1 Running 1 6d12h
metallb-operator-controller-manager-f4f5b9865-2c6nl 1/1 Running 1 6d12h
metallb-operator-webhook-server-bf55c447b-x5nnv 1/1 Running 1 6d12h
speaker-67k7x 1/1 Running 7 (6d12h ago) 28d
speaker-6v5lv 1/1 Running 6 (6d12h ago) 28d
speaker-rp4k8 1/1 Running 7 (6d12h ago) 28d
speaker-stnkv 1/1 Running 92 (5m35s ago) 28dLogs of the speaker pods expose errors to read configMap information from the namespace causing them to crash and get restarted ad infinitum:
W0407 06:01:21.839577 1 reflector.go:424] pkg/mod/k8s.io/client-go@v0.26.0/tools/cache/reflector.go:169:
failed to list *v1.ConfigMap: configmaps is forbidden: User "system:serviceaccount:metallb-system:speaker"
cannot list resource "configmaps" in API group "" in the namespace "metallb-system"Workaround
Edit the clusterroles.authorization.openshift.io and add the permission to read configmap objects to the service account metallb-system:speaker
Root cause
The root cause has been identified in the deployment of the metallb services, which use containers from the main tag of the repository, causing nightly builds of the development branch of the containers ending up getting deployed uncontrollably to the OKD cluster. Also version differences of the running containers are possible, leading to an undefined metallb cluster state.
* https://quay.io/repository/metallb/speaker?tab=tags
Resolution
Change the tag of the deployments to a stable release version (v0.13)
Follow-up tasks
- Update documentation
- Implement monitoring/alerting solution: /boards/team/kxr1rdhhqtb47muhr3kucn5mxe/bnqecfsesxi8x3pkdm6ahbqf1gy/v48sbw7m8hfn95y9u78fezy3s6o/cc1fh1fw1qi8mmguuje55zr1i3a