Mastodon sidekiq autoscaling with the KEDA operator
This article assumes Mastodon is installed as a containerized setup on top of e.g. Kubernetes (k0s/k3s/k8s), Rancher, Openshift, etc.
Creating a kubernetes cluster or deploying Mastodon on kubernetes via helm is out of scope of this article.
IntroductionProbably any Mastodon administrator who has seen some (or rapid) growth of their instance has experienced the same issue: growing latency of posts, updates from other servers showing up late or not at all, image uploads not getting processed etc.
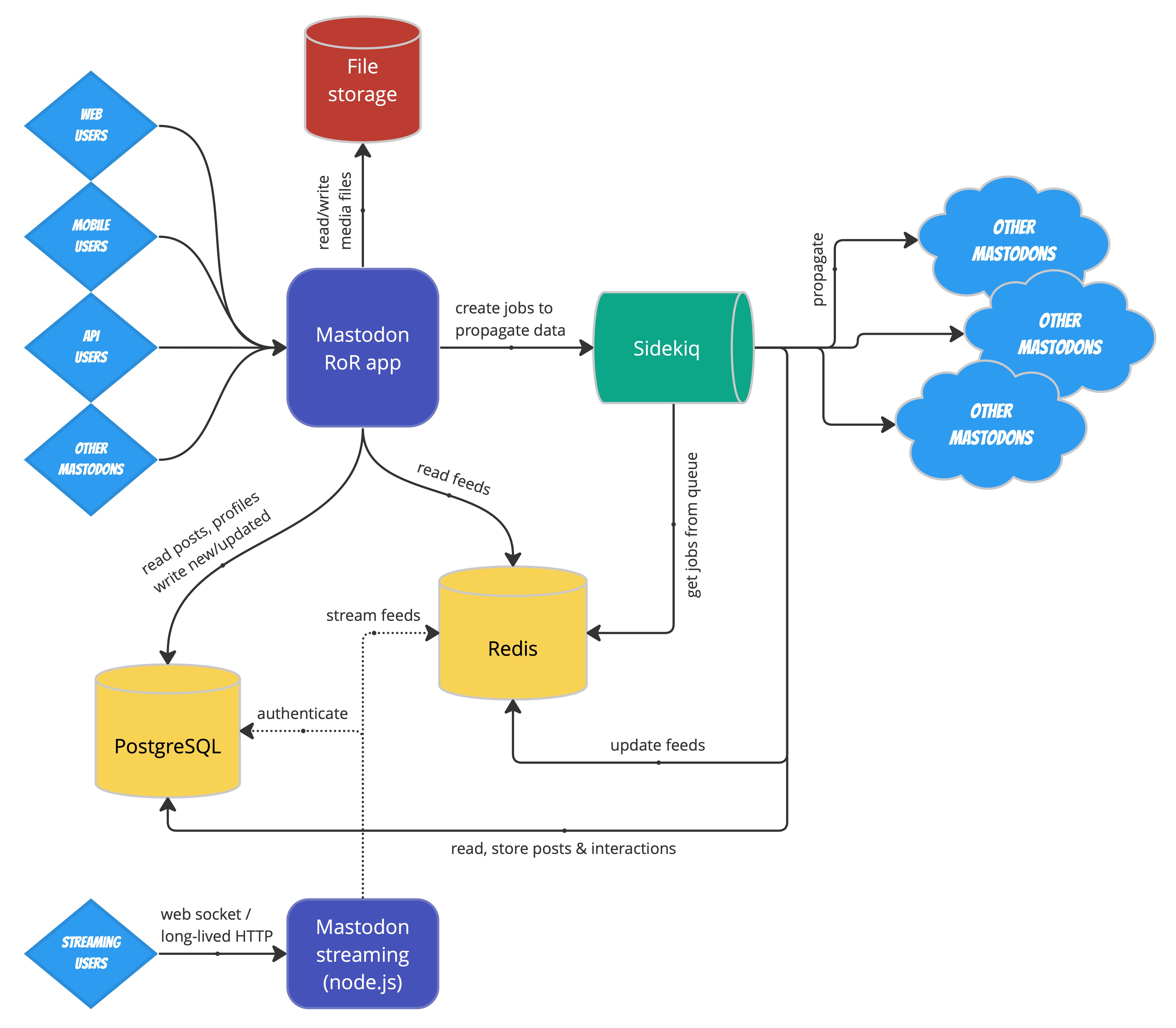
The root of this issue lies in the architecture of Mastodon. Every time a new action (create post, upload image, interact with other instance,...) happens on a Mastodon instance, it is not processed immediately, but put into a job queue. This queue consists of two pieces of software: the Sidekiq job queue and the Redis database.
Depending on how busy an instance is, any default Mastodon setup will most likely run into above mentioned issues as its user base grows, since the default setup of the job queue can only cope with a moderate amount of requests before it will be overwhelmed and the job "pipes" will literally get clogged up. |
User reporting growing latencies (German) |
Architecture overview
Flow of actions ("jobs") through a Mastodon instance, On the right-hand side of the overview we can see the Sidekiq and Redis components. |
Mastodon architecture, courtesy of Softwaremill / Adam Warski (c) 2022
|
Mastodon kubernetes installation
The recommended way of deploying Mastodon on kubernetes is via the official Mastodon helm chart Depending on the chosen configuration of the chart, this will produce several kubernetes objects for all the necessary services needed to run a Mastodon instance.
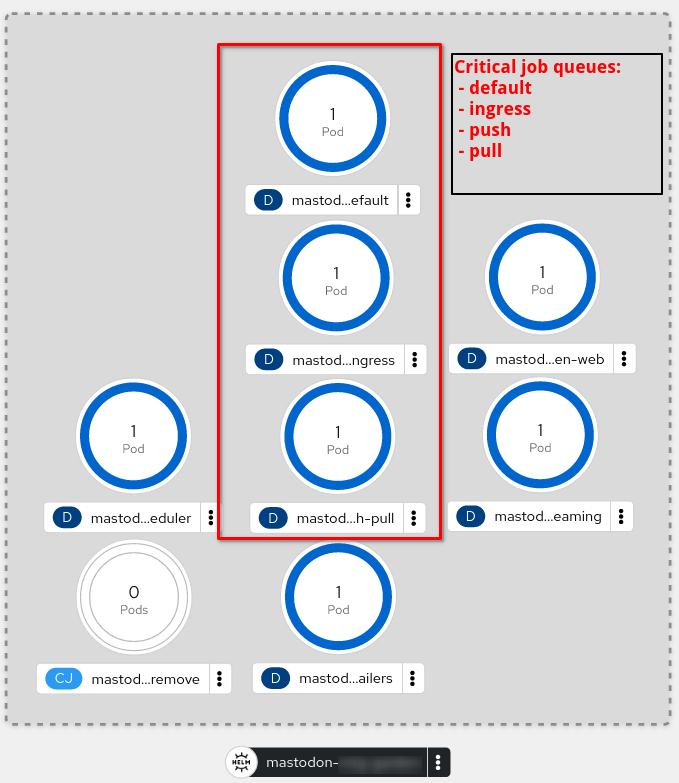
The objects we are interested in for this article are the Sidekiq containers ("pods") which handle different kinds of tasks. again, depending on the helm configuration, those queues can be spread out over multiple pods, e.g.:
See Mastodon's documentation on queues to understand what these do in detail. For now let's focus on the default, ingress and push/pull queues, as those are the most important ones.
Although a single pod can be configured to handle different queues in parallel, it is highly recommeded to separate these pods by queue type to enable the desired scale-out capabilities.
|
Openshift "Developer" view of a Mastodon installation, deployed via helm. Image courtesy of b2c@dest-unreachable.net (c)2023 |
ChallengeNow, depending on the usage pattern of the instance, the time of day and possibly many other factors, different queues will see varying amount of load. Certain events (posts going viral, major news events, etc.) may even cause temporary peak loads that will subside quickly.
Although monitoring solutions can (and should!) be put in place to detect such scenarios, admin interaction will still be required to scale up the deployments of the pods handling the affected queues. This usually leads to over-provisioning - scaling up the different deployments permanently to prep for such situations just in case. This of course can be costly on resources, and is technically not sound. We should be able to do better.
But what if we had something to check the current load of the queue in Redis and scale pods accordingly? Of course we could have the kubernetes built-in
|
See also: |
SolutionAutoscaling Sidekiq pods will create additional connections to the PostgreSQL database. Ensure your connection limit is high enough and/or deploy a connection pool (e.g. PgBouncer).
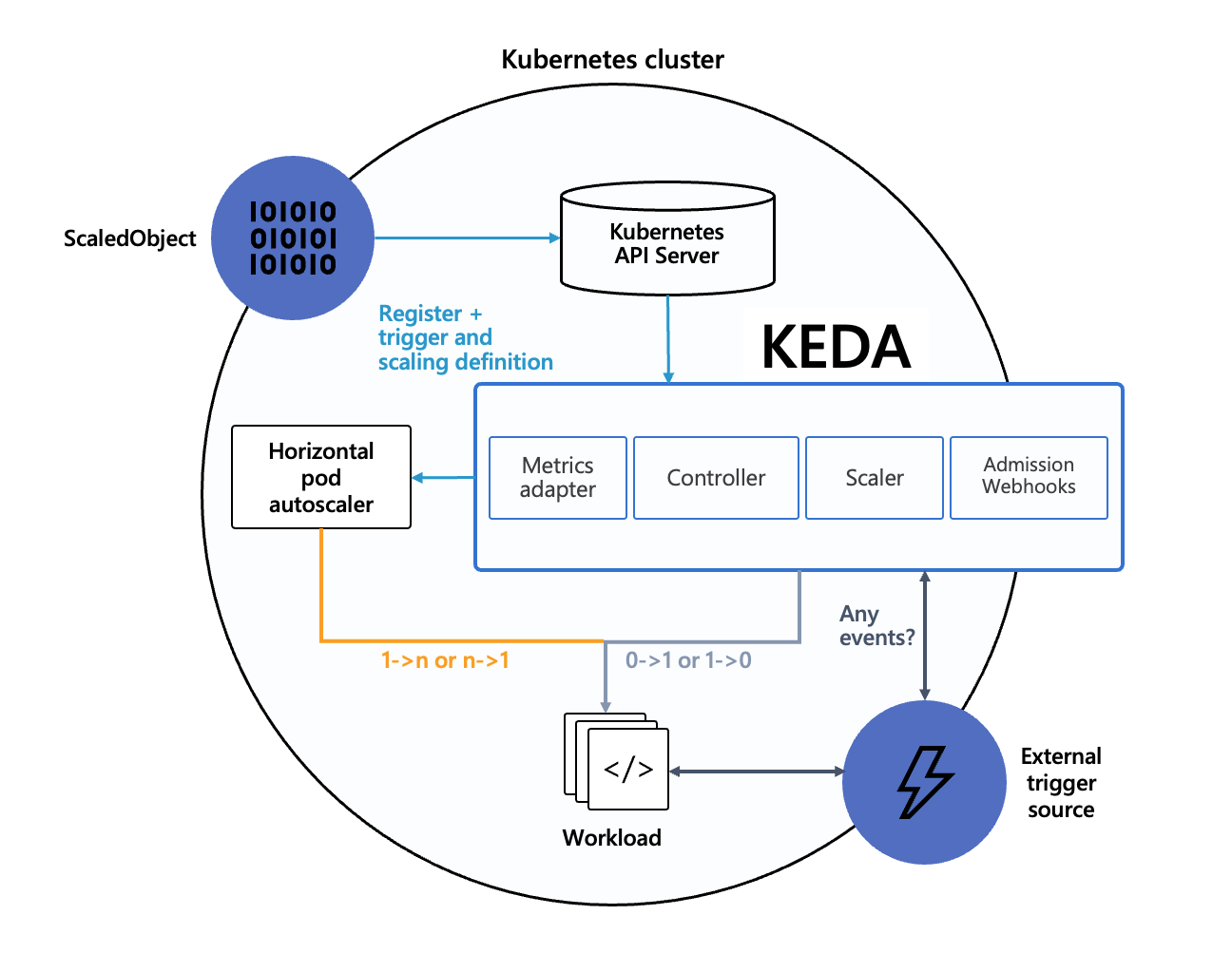
In steps the KEDA operator , an event-driven autoscaler which can collect metrics from resources outside the cluster, and scale pods based on this information.
Specifically, we are interested in the amount of jobs in the Redis queues. Luckily, KEDA has a scaler just for this: the Redis lists scaler, which we will utilize to scale our deployments without any admin interaction necessary.
Sweet! But how does one do it?
|
|
ImplementationTo get this working, we need to get two things done:
|
|
Installing the operator
Installing the operator is straightforward and works as advertised in the KEDA documentation. Again, weutilize helmto deploythe
|
This has been confirmed working on:
Operator installation: |
Creating the HPA objects
Initially, we will need a way to authenticate to Redis. This can be achieved by creating a triggerAuthentication object which refers to the secret holding the Redis database password.
KEDA uses so called scaledObject definitions, which in turn will create horizontalPodAutoscalers to scale our workloads.
In the example configuration, we start to scale up our deployment when the amount of jobs in the default queue reaches 1500.
If this is not enough to reduce the jobs in the queue below the threshold, every other minute another pod will be deployed, up to a maximum of four.
If, for any reason, the HPA should fail, the deployment will be scaled to two pods to avoid an outage of the service until the issue can be inspected and rectified.
Example triggerAuthentication :
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: trigger-auth-redis-secret
namespace: mastodon
spec:
secretTargetRef:
- key: redis-password
name: mastodon-database-secrets
parameter: password
Example scaledObject :
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
labels:
scaledobject.keda.sh/name: mastodon-sidekiq-worker-default
name: mastodon-sidekiq-worker-default
namespace: mastodon
spec:
advanced:
horizontalPodAutoscalerConfig:
behavior:
scaleUp:
policies:
- periodSeconds: 60
type: Pods
value: 1
stabilizationWindowSeconds: 300
cooldownPeriod: 300
maxReplicaCount: 4
minReplicaCount: 1
pollingInterval: 30
fallback:
failureThreshold: 3
replicas: 2
scaleTargetRef:
kind: Deployment
name: mastodon-sidekiq-worker-default
triggers:
- authenticationRef:
name: trigger-auth-redis-secret
metadata:
address: 10.10.10.50:6379
listLength: "1500"
listName: queue:default
metricType: Value
type: redisThese are just some examples!
Adjust name, namespace, IP address and port of Redis, etc. to your specific setup.
Testing the setup
After
Additional caveats
Depending on setup specifics, certain parts of the configuration should be adjusted.
Considerations regarding Redis namespaces:
Considerations regarding pods with multiple Sidekiq roles:
It is a common practice to have the push and pull queues handled by one pod. In this case, triggers for both queues must be defined in the scaledObject - triggers is a YAML list and can hold more than one entry.
Considerations regarding performance and pod count:
If REDIS_NAMESPACE is defined in the environment, listName must be adjusted to reference the namespace:listName: <REDIS_NAMESPACE>:queue:default
E.g. if REDIS_NAMESPACE=masto5 , then set listName to:listName: masto5:queue:default
Just add additional definitions in the triggers part of the definition:
triggers:
- authenticationRef:
name: trigger-auth-redis-secret
metadata:
address: 10.10.10.50:6379
listLength: "1500"
listName: queue:push
metricType: Value
type: redis
- authenticationRef:
name: trigger-auth-redis-secret
metadata:
address: 10.10.10.50:6379
listLength: "1500"
listName: queue:pull
metricType: Value
type: redis
The referenced values for pod count, amount of jobs in the queue, when to scale up or down, or the time between scale operations are highly dependent on the underlying hardware and overall utilization of the cluster.
They have proven sufficient in the author's setup and can be used as a starting point, but most likely will need to be adjusted.